Вільне програмне забезпечення OCR для вилучення тексту з файлів зображень і предметів PDF. Графічний інтерфейс користувача (GUI) для двигуна Tesseract OCR.
Додаток проста в установці і, що більш важливо, вільно використовувати, з відкритим вихідним кодом і 100% рекламного і шпигунського ПЗ безкоштовно.
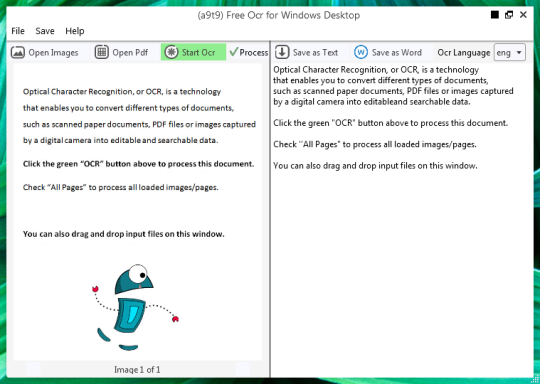
Ви можете відкрити файл зображення або PDF. Зміст початкового файлу буде відображатися в лівому вікні. Якщо ваш документ як більш ніж на одній сторінці, або якщо ви відкрили багатосторінкових документів за допомогою стрілок внизу, щоб перемикатися між ними,
Ви починаєте OCR, натиснувши на зелену кнопку OCR, і ви побачите результат в другому правому вікні. Виведення тексту може бути збережений у вигляді текстового файлу або документа Word.
На жаль якість перетворення не так вже й велика. За сценою він використовує з відкритим вихідним кодом OCR Engine TESSERACT. Якість варіюється від мови до мови. - Щоб йти вперед і перевірте це достатньо для ваших потреб
Для розробників програмного забезпечення і вундеркіндів: безкоштовна OCR для інструменту робочого столу Windows, по суті, графічний користувальницький інтерфейс передній кінець (GUI) для двигуна Tesseract OCR. Повний вихідний код є (ліцензія GPL).
Двигун OCR програмного забезпечення підтримує наступні мову OCR: англійська, французька, італійська, німецька, іспанська, бразильський португальська і голландський. Починаючи з версії 3 можна визнати арабська, болгарська, каталанська, китайська (спрощена і традиційна), хорватська, чеська, датська, голландська, англійська, німецька (стандартний і Fraktur скрипт), грецька, фінська, французька, іврит, хінді, угорська, індонезійська, італійська, японська, корейська, латиська, литовська, норвезька, польська, португальська, румунська, російська, сербська, словацька (стандартний і Fraktur скрипт), словенська, іспанська, шведська, тагальська, тамільська, тайська, турецька, українська та в'єтнамський.
Коментар не знайдено