Великі дані - це маркетинговий термін, який охоплює ідею вилучення даних з джерел, таких як пошукові системи, схеми покупки продовольчих магазинів, відстежуваних за картками точок тощо. У сучасному світі Інтернет має так багато джерела даних, що частіше за все масштаб робить його непридатним без обробки і обробки, який займе незрівнянно багато часу на будь-якому одному сервері. Введіть Apache Hadoop
Менш час для обробки данихВикористовуючи архітектуру Hadoop для розповсюдження обробки завдань на декількох машинах у мережі , час обробки зменшується астрономічно, а відповіді можна визначити в достатній кількості часу. Apache Hadoop поділяється на два різних компоненти: компонент зберігання та компонент обробки. У найпростіших випадках, Hapood робить одним віртуальним сервером з декількох фізичних машин . Насправді, Hadoop керує зв'язком між кількома машинами таким чином, що вони працюють разом досить близько, щоб вони виглядали так, начебто на вирахуванні існує лише одна машина. Дані поширюються на декількох машинах для зберігання та завдання обробки виділяються та координуються архітектурою Hadoop
. Цей тип системи є необхідною умовою для перетворення вихідних даних у корисну інформацію у масштабі великих входів даних. Розгляньте кількість даних, які Google отримує щосекунди від користувачів, які вводять пошукові запити. Як загальний обсяг даних ви б не знали, з чого почати, але Hadoop автоматично зменшить набір даних у менші, організовані підмножини даних і призначає це кероване підмножина для певних ресурсів. Потім всі результати надсилаються назад і збираються в інформацію про використання .
Сервер легко встановлюється
Незважаючи на те, що система звучить складно, більшість рухомих частин затуманено позаду абстракції. Налаштування сервера Hadoop досить простий , просто встановіть компоненти сервера на апаратне забезпечення, яке відповідає системним вимогам. Найважча частина проектує мережу комп'ютерів , щоб сервер Hadoop використовуватиметься для розподілу ролей зберігання та обробки. Це може включати в себе налаштування локальної мережі або підключення кількох мереж через Інтернет . Ви також можете використовувати існуючі хмарні сервіси та платити за кластер Hadoop на популярних хмарних платформах, таких як Microsoft Azure та Amazon EC2. Ці налаштування ще легше, тому що ви можете їх обертати спеціально, а потім вимкнути кластери, коли вам більше не потрібні. Ці типи кластерів ідеально підходять для тестування, оскільки ви платите лише за час активності кластера Hadoop.
Обробіть свої дані, щоб отримати необхідну інформацію
Великі дані є надзвичайно потужним ресурсом, але дані стають марними, якщо вони не можуть бути належним чином класифіковані та перетворені в інформацію. На даний момент кластери Hadoop пропонують надзвичайно економічний метод для обробки цих збірок даних у інформацію.
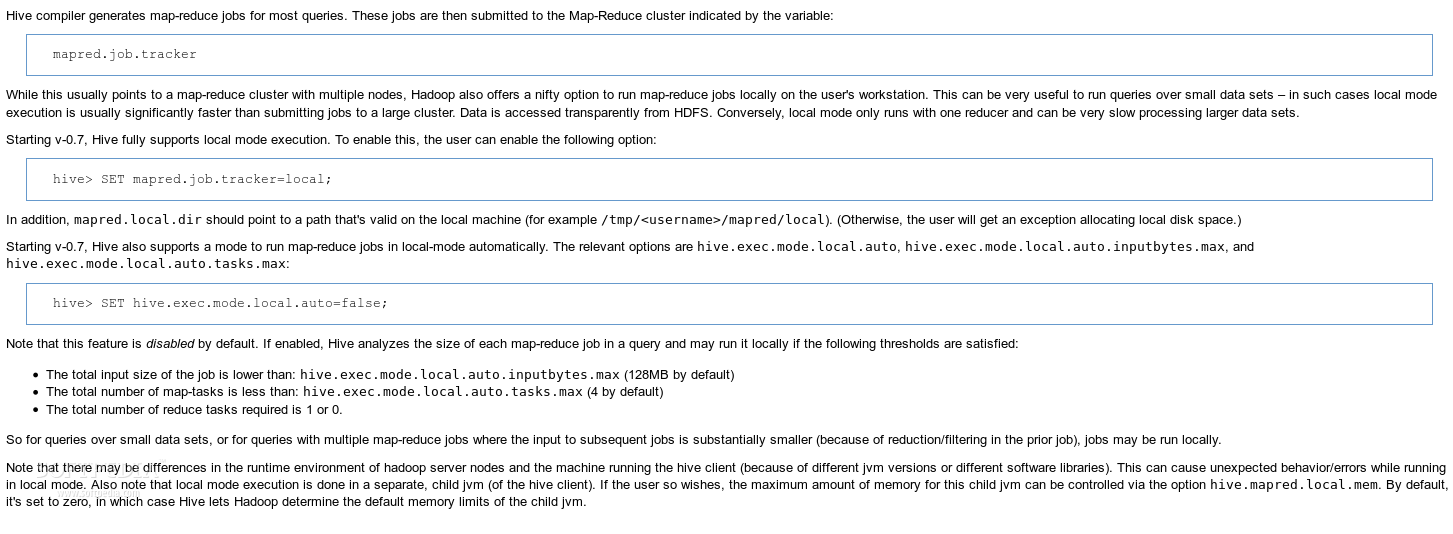

Коментар не знайдено