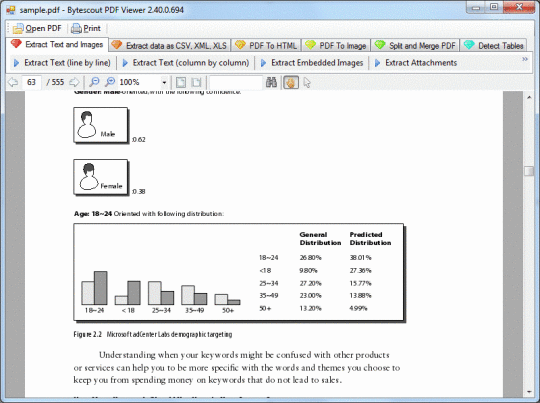
Багатофункціональний PDF-файл (FREEWARE) включає набір функцій для вилучення даних і тексту з PDF-файлів: PDF в XML, PDF в CSV, PDF в текст, читання тексту з сканованого PDF-файлу з використанням OCR, пошук тексту з регулярним виразом, витягування оригінальних зображень і набагато більше! Включає підтримку OCR (читання тексту з зображень) на англійську, німецьку, французьку, іспанську мови.
Інші функції:
вилучає накладення файлів;
витягує файли з пакетів PDF;
витягує дані FDF та XFA з форматів PDF;
вилучає дані рахунків ZUGFeRD як XML;
розділяє, зливає сторінки з PDF-файлу.
Що нового в цьому випуску:
Версія 8.7.0.2918 може містити невизначені оновлення, удосконалення або виправлення помилок.
Що нового в версії 8.6.0.2916:
Версія 8.6.0.2916: оновлений движок OCR до останньої версії;
фіксовані проблеми розбору PDF;
фіксовані шрифти;
фіксовані декодування JBIG-зображень;
інші незначні покращення та виправлення помилок.
Що нового у версії 8.0.0.2528:
Інші незначні покращення та виправлення помилок.
Що нового у версії 6.30.0.2421:
Коментар не знайдено