
PDF OCR є простою перетягнути і падіння утиліта, яка перетворює ваші PDF-файли та зображення в текст або пошуку документів PDF. Вона використовує передові OCR (оптичне розпізнавання символів) технології для вилучення тексту з PDF (або зображення), навіть якщо цей текст міститься в зображенні. Це особливо корисно для боротьби з PDF-файлів і зображень, які були створені за допомогою функції сканування в PDF в сканер або фото копіювального апарату. Підтримка більше 20 мов для розпізнавання тексту. Двигун розпізнавання заснований на Tesseract. Community Edition підтримує одній сторінці PDF-файлів (або на першій сторінці багатосторінкові PDF-файлів). Для багатосторінкового PDF підтримку, яку ви повинні перейти на Enterprise Edition. Community Edition підтримує файли зображень і окремими сторінками PDF-файлів. Для багатосторінкових файлів PDF, скачати Enterprise Edition
Що нового У цьому випуску :.
Версія 2.0.8 додана підтримка кирилиці тексту в пошук Висновок PDF. Також виправлена помилка з обробкою деяких PDF-файлів з безліччю обертання.
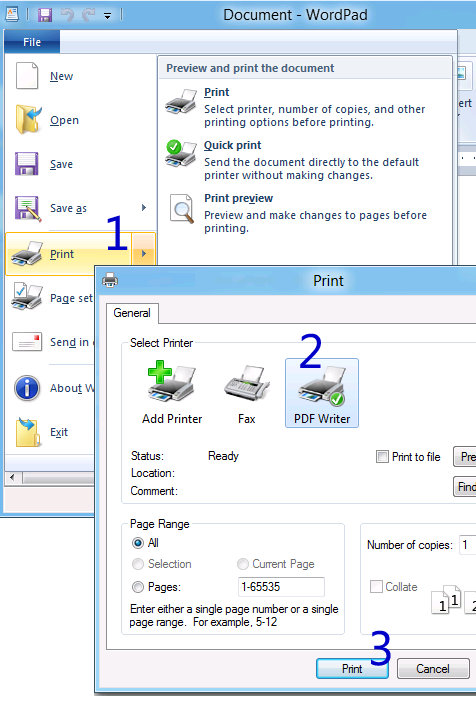
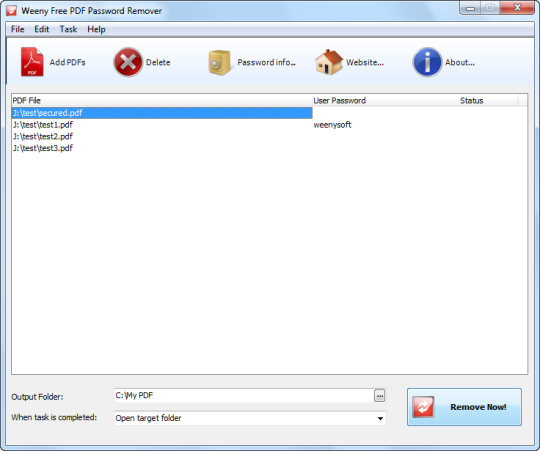





Коментар не знайдено