
PDF Extractor SDK для розробників програмного забезпечення Windows: PDF в текст, PDF в XML, зображення з PDF, читання PDF-інформації, PDF в CSV для Excel.
Bytescout PDF Extractor SDK дозволяє конвертувати PDF в текст, PDF в XML, PDF в CSV, витягувати зображення з PDF, витягувати інформацію про файли PDF у інтерфейсах .NET та ActiveX без будь-якого додаткового програмного забезпечення.
Переваги:
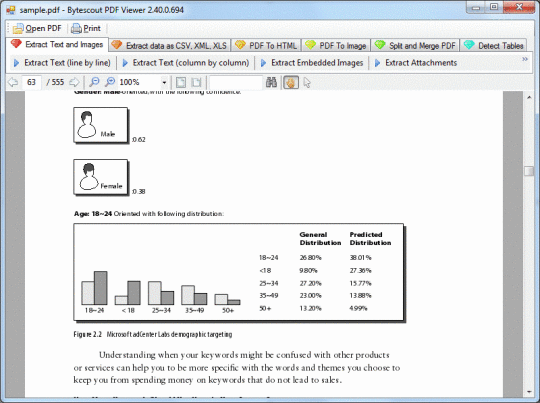
перетворює PDF у звичайний текст (і може слідувати стовпцям, якщо ви конвертуєте газету у форматі PDF) - у тому числі невидимий видобуток тексту;
перетворює таблиці в форматі PDF в Excel (CSV), читаючи комірки з заданого прямокутника;
перетворює таблиці в PDF у файли XML;
витягує метадані файлів PDF (заголовок, автор, опис) та отримує іншу інформацію про файл (кількість сторінок, зашифрована чи ні);
витягує вбудовані зображення з документа PDF (у ASP.NET, VB.NET, C #, VB6 та VBScript);
DocumentMerger та DocumentSplitter інтерфейси та класи для злиття та розбиття документів PDF;
не вимагає встановлення Adobe Reader або будь-якого іншого програмного забезпечення для читання PDF;
надає інтерфейси .NET та ActiveX;
з 100% керованим кодом C #.
Що нового у цьому випуску:
Версія 9.0.0.3079: Додана фільтрація вилученого вмісту за назвою шрифту, розміром шрифту та кольором.
Оновлений двигун OCR до останньої версії. Оновіть мовні файли з папки "tessdata".
Покращена вилучення тексту, групування рядків у табличних даних, продуктивність, вилучення форм XFA, TableDetector, фіксовані проблеми розбору PDF.
Що нового в версії 8.7.0.2980:
Додана фільтрація вилученого вмісту за назвою шрифту, розміром шрифту та кольором.
Оновлений двигун OCR до останньої версії. Оновіть мовні файли з папки "tessdata".
Покращено вилучення тексту, згрупування рядків у табличних даних, продуктивність, вилучення форм XFA, TableDetector, фіксовані проблеми синтаксичного аналізу PDF.
Що нового в версії 8.6.0.2911:
Додана фільтрація вилученого вмісту за назвою шрифту, розміром шрифту та кольором.
Оновлений двигун OCR до останньої версії. Оновіть мовні файли з папки "tessdata".
Покращено вилучення тексту, згрупування рядків у табличних даних, продуктивність, вилучення форм XFA, TableDetector, фіксовані проблеми синтаксичного аналізу PDF.
Що нового у версії 8.2.0.2699:
Версія 8.2.0.2699 може містити невизначені оновлення, удосконалення або виправлення помилок.
Що нового в версії 8.0.0.2528:
Що нового в версії 7.0.0.2474:
Версія 7.0.0.2474:
- додано новий клас Утиліта DocumentPrinter, що дозволяє друкувати PDF-документи без використання (без будь-яких діалогів користувача).
- додано новий клас JSONExtractor
- додано переопределення для методу DocumentSplitter.Split (), що дозволяє вказати вихідну папку для згенерованих файлів
- виправлено багато помилок в DocumentSplitter
- tableDetector тепер дотримується області вилучення, заданої методом SetExtractionArea ()
- нові властивості в класах вилучення: ExtractionColumns - містить координати виявлених стовпців; CustomExtractionColumns - дозволяє переопределити виявлення стовпців
- Методи GetPageRect * не враховували обертання сторінки.
Виправлена помилка в програмі установки, через яку деякі файли з попередньої інсталяції перешкоджали оновленню - переробив перевірку реєстрації. Тепер бібліотека не викине виняток, але працюватиме в демо-режимі, якщо ви пропустили або неправильно ввести реєстраційне ім'я та реєстраційний ключ
- Багатофункціональний інструмент PDF: Додано список останніх документів на "Відкрити PDF-документ"
- Багатофункціональний інструмент PDF: тепер можна змінити розмір вибірки
- Багатофункціональний інструмент PDF: додано Витягувати функцію JSON
- Багатофункціональний інструмент PDF: покращений інтерфейс користувача детектора таблиць
- Багатофункціональний інструмент PDF: значно покращена якість рендеринга шрифтів
- PDF Multitool: додано параметр налагодження "Показати виявлені стовпці вилучення" у контекстне меню, щоб відобразити виявлені стовпці на поточній сторінці. Стає видимим лише після виконання будь-якої витяжки до поточної відображеної сторінки
- Багатофункціональний інструмент PDF: Виправлена проблема рендеринга шрифтів на 32-розрядній системі Windows
- інші незначні покращення та виправлення помилок
Що нового у версії 6.30.0.2421:
Версії 6.30.0.2421:
- Додано клас утиліти TextComparer (доступно лише в збірках .NET 4.0), що дозволяє порівнювати текст у двох документах PDF та створювати звіти.
- Покращена підтримка кольорових профілів ICC.
- Імпортова обробка вбудованих шрифтів.
- Покращений додатокextractor.
- Виправлено метод XMLExtractor.SaveXMLToStream ().
- Виправлено вилучене дублювання тексту при використанні опції OCRCacheMode.WholePage.
- Інші виправлення та покращення помилок.
Що нового у версії 6.20.2354:
Версія 6.20.2354:
- Покращена функція PDF для тексту, PDF у форматі CSV, PDF для функції XML
- Новий витяг відео, вилучення звукових прикладів
- Екстрактори CSV та XML вдосконалили підтримку таблиць з порожніми стовпцями всередині
- новий MultimediaExtractor для вилучення відео та аудіо з PDF
- нове властивість PageDataCaching
- новий приклад "MemoryCareProcessingOfHugeFiles"
- виправлено недійсне виключення при спробі розпоряджатися вже розміщеними сторінками
- XLSExtractor: покращує підтримку шрифтів
- SkipInvisibleText тепер пропускає обрізаний текст (який не видно)
- поліпшення рендеринга текстового виводу
- XFDF Extractor: додано підтримку прапорців
- Покращено вивід зображень для підтримки більшості під-форматів
- Удосконалення обробки текстів у форматі Unicode
Що нового в версії 6.11.2149:
Версія 6.11.2149:
- Зразки пакетної обробки оновлено, щоб показати використання методу Reset ()
- Зразок вихідного коду C ++ додано для вилучення сторінок
- DocumentMerger додає Merge2 (файл inputfile1, inputfile2, outputfile) метод для об'єднання 2 файлів
- Виправлені помилки виправлення XLS Extractor
- Тепер програма PDF Multitool дозволяє вмикати / вимикати текстові, графічні, векторні шари, додавати розширені параметри для вилучення тексту
- XML, CSV, Extracting Table покращує підтримку таблиць з комірками emtpry усередині стовпців
- . Виправлено властивість .ExtractShadowLikeText: краще фільтрувати для тіні
Що нового в версії 6.10.2136:
Версія 6.10.2136:
- PDF-файл у форматі XML, PDF-файл у форматі CSV, функціональність PDF-тексту до тексту покращено
- додано зразок командного рядка PDF до XLS (на базі vbscript)
- PDF до HTML SDK додає новий властивість .TextHyperLinks (TRUE за замовчуванням), щоб увімкнути / вимкнути виявлення автоматичних посилань у тексті
- новий SearchablePDFMaker (доступний для ліцензій PRO) для перетворення PDF у PDF-файли, які можна шукати
- нові властивості в екстрактор: ConsiderFontNames, ConsiderFontSizes, ConsiderFontColors, ConsiderVerticalBorders у файлах CFG
- виявлення стовпців заголовків (коли AutoAlighHeaderToColumns = true) покращено
- .DetectLinesInsteadOfParagraphs замінені новими. LineGroupingMode, щоб контролювати, як лінії об'єднуються в абзаци
- ВАЖЛИВО! PDF для XML фіксує довготривалу проблему з неправильною координатою Y для текстових об'єктів (мала місце внизу ліворуч, а не ліворуч угорі).
- Заповнені властивості .TableXMinIntersectionRequiredInPercents та .TableYMinIntersectionRequiredInPercents.
- додано вихідний код C ++
- XML Extractor виправляє відсутні порожні колонки в режимі PreserveFormatting = true
- незначні виправлення кольорів у деяких PDF-файлах
- підтримка декількох мов OCR додана
- Багатофункціональний інтерфейс PDF: додавання кнопки Копіювати в буфер обміну у діалогові вікна TXT, CSV, XML та растрові візуалізатори
- XLSExtractor: додає властивість PageToWorksheet, щоб включити / вимкнути генерацію окремих аркушів на кожній сторінці
- новий властивість .TextEncodingCodePage
- PDFViewerControl: додає ValidateContextMenu, що дозволяє користувачеві додавати власні елементи в контекстне меню
- Контроль PDF-переглядача: додає властивості ShowTextObjects, ShowImageObjects, ShowVectorObjects
- XMLExtractor тепер додає атрибут "OCRConfidence" для розпізнаного тексту
- функціональність перевірки PDF / A (в бета-версії)
- поліпшення елементів керування та перевірка тексту та вирівнювання за оригінальним макетом. Питання було спричинено зміщенням координат Y в контролі під час аналізу: це було неправильно. Правильний спосіб - перемогти ...
- Оновлений XML Extractor: тепер створює тег CONTROL для прапорців та текстових полів
- змінено використання поточного каталогу в каталог temp
- прапорці, радіобік, редагування, комбінації, краще підтримуються
- тепер дозволяє частково довіряти абонентам
Що нового в версії 5.80.1781:
Версія 5.80.1781:
- оновлено PDF-файл у форматі XML, PDF-файл у форматі CSV, функція PDF-файл у текстовому форматі
- Тепер у OCRMode передбачено 9 режимів
- .DetectLineInsteadOfParagraph тепер працює набагато краще. Встановіть його в значення "Невірний" для зйомки багаторядкового тексту в клітинках таблиці!
- Підтримка керування PDF удосконалена
- Витяг даних FDF та XFDF
Що нового в версії 5.10.1747:
Версія 5.10.1747:
- Покращено PDF-файли у форматі XML, PDF-файли у форматі CSV, PDF-файлів у текстовому форматі
- тепер підтримує вилучення тексту з текстових елементів керування
- XML Extractor тепер додає стиль шрифту, розмір, ім'я, текстові координати в теги
- Зразок ASP.NET для використання OCR додано
- Нова властивість OCRLanguageDataFolder для визначення розташування папки "tessdata"
- покращена підтримка PDF-файлів
- покращує підтримку повороту тексту
- оновлені зразки вихідного коду
- оновлена документація
- незначні покращення та виправлення
Що нового у версії 5.00.1626:
Версія 5.00.1626:
- Додано функцію розпізнавання тексту (текст з малюнків): тепер ви можете витягувати текст із вбудованих зображень та відремонтувати пошкоджений текст
- Виправлена помилка вилучення останніх стовпців з деякими налаштуваннями за допомогою CSV та XML extractor
- покращена підтримка пошкоджених PDF-файлів
- Тепер підтримується багатолітерний текстовий пошук з використанням режимів зіставлення слів
- тепер може шукати текст з дефісами і по різних рядках: переглянути новий зразок вихідного коду Знайти текст із дефісами
- нове властивість .RTLTextAutoDetectionEnabled (за замовчуванням помилково) автоматично виявляти мови RTL
- Графічний інтерфейс програми PDF Viewer поліпшено
- незначні покращення та виправлення
Вимоги :
.NET Framework 2.0 або пізніші
Обмеження :
Над екран, водяний знак на виході

Коментар не знайдено